
In this blog post, we will walk through a Python script that extracts and processes tax rate data from PwC’s tax summaries website. We will cover the following steps:
- Scraping tax data from the website.
- Parsing and cleaning the data using BeautifulSoup and pandas.
- Combining and organizing the data for analysis.
Introduction
Analyzing global tax rates can provide valuable insights for businesses and individuals alike. With the help of Python and libraries like pandas and BeautifulSoup, we can automate the process of collecting and cleaning this data from online sources. Let’s dive into the script and see how it’s done.
Prerequisites
Before we start, make sure you have the following libraries installed:
pip install pandas numpy requests beautifulsoup4The Script
Here’s the complete script to scrape, process, and analyze tax rates:
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
def get_tax_rates(url):
response = requests.get(url)
if response.status_code == 200:
# Parse the content using Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all <table> tags with class "table"
tables = soup.find_all('table', class_='table')
# List to store DataFrames for each table
df_list = []
# Iterate over each table
for idx, table in enumerate(tables):
# List to hold rows of the table
table_data = []
# Extract headers
headers = [header.get_text(strip=True) for header in table.find_all('th')]
# Iterate over each row in the table
for row in table.find_all('tr'):
# Get all columns in the row
cols = row.find_all(['td', 'th'])
# Extract text from each column
col_texts = [col.get_text(strip=True) for col in cols]
table_data.append(col_texts)
# Create a DataFrame
df = pd.DataFrame(table_data)
# Set the first row as header if headers are present
if headers:
df.columns = headers
df = df[1:] # Remove the header row from the data
# Append the DataFrame to the list
df_list.append(df)
# Optionally, concatenate all DataFrames into one
df = pd.concat(df_list, ignore_index=True)
df = df.join(df['Territory'].str.split('(', expand=True).add_prefix('cupdate'))
df.drop(columns=['Territory','cupdate2'],inplace=True)
df.rename(columns = {'cupdate0':'country','cupdate1':'last_reviewed'},inplace=True)
df.columns = df.columns.str.replace(' ','_').str.lower()
df.last_reviewed = df.last_reviewed.str.replace('Last reviewed ','').str.replace(')','')
df.last_reviewed = pd.to_datetime(df.last_reviewed,errors='coerce')
try:
df['pit_rate']=pd.to_numeric(df['headline_pit_rate_(%)'],errors='coerce')
df['comment'] = np.where(df.pit_rate.isna(),df['headline_pit_rate_(%)'],None)
df.drop(columns=['headline_pit_rate_(%)'],inplace=True)
except:
pass
try:
df['cit_rate'] = pd.to_numeric(df['headline_cit_rate_(%)'], errors='coerce')
df['comment'] = np.where(df['cit_rate'].isna(), df['headline_cit_rate_(%)'], None)
df.drop(columns=['headline_cit_rate_(%)'], inplace=True)
except:
pass
try:
# Convert 'headline_pit_rate_(%)' to numeric, handle errors with NaN and create 'comment' column
df['vat_rate'] = pd.to_numeric(df['standard_vat_rate_(%)'], errors='coerce')
df['comment'] = np.where(df['vat_rate'].isna(), df['standard_vat_rate_(%)'], None)
df.drop(columns=['standard_vat_rate_(%)'], inplace=True)
except:
pass
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
return df
url1 = 'https://taxsummaries.pwc.com/quick-charts/corporate-income-tax-cit-rates'
url2 = 'https://taxsummaries.pwc.com/quick-charts/personal-income-tax-pit-rates'
url3 = 'https://taxsummaries.pwc.com/quick-charts/value-added-tax-vat-rates'
df = get_tax_rates(url1)
df2 = get_tax_rates(url2)
df3 = get_tax_rates(url3)
df = df.merge(df2,left_on='country',right_on='country').merge(df3,left_on='country',right_on='country').drop(columns=['last_reviewed_x','last_reviewed_y'])
df.rename(columns={'cit_rate':'coorporate_tax','pit_rate':'personal_tax','vat_rate':'vat'},inplace=True)
df = df[['country','last_reviewed','coorporate_tax','comment_x','personal_tax','comment_y','vat','comment']]
df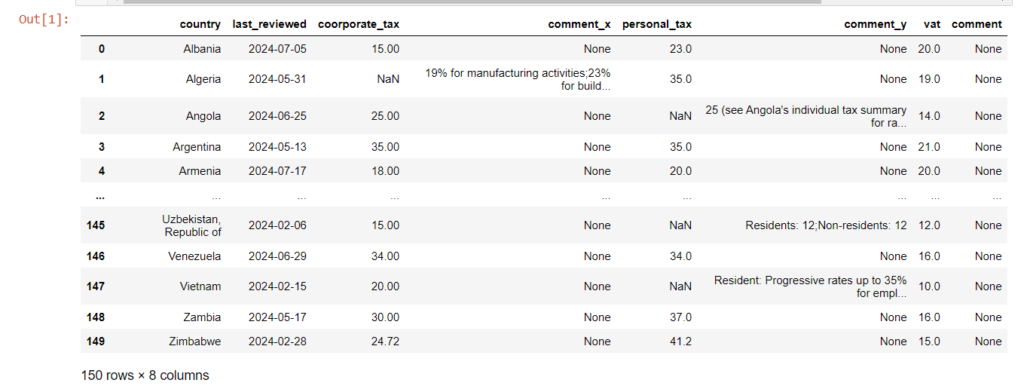
Conclusion
By following this guide, you can automate the process of scraping, cleaning, and analyzing tax rate data from online sources. This script can be customized to fit your specific needs and extended to include additional data points or analyses. Happy coding!